
Investment in Fast Data Processing Growing: Survey
While Big Data still garners the lion's share of attention, companies are increasingly looking to so-called fast data for real-time streaming data analytics to give them a competitive edge.
“We are seeing so many use cases and business applications across different industries in which companies are using the ability to process huge streams of data in real time to gain competitive advantage,” said Sachin Agarwal, VP of Marketing for OpsClarity, a provider of monitoring software for streaming data applications that recently published a report titled 2016 State of Fast Data and Streaming Applications.
For example, he said, e-commerce companies use streaming data analytics to create targeted advertising and real time promotional offers for online shoppers and financial institutions use it to identify card fraud.
[Related:How to Sell Overseas: 5 Best Practices for Fast Data]
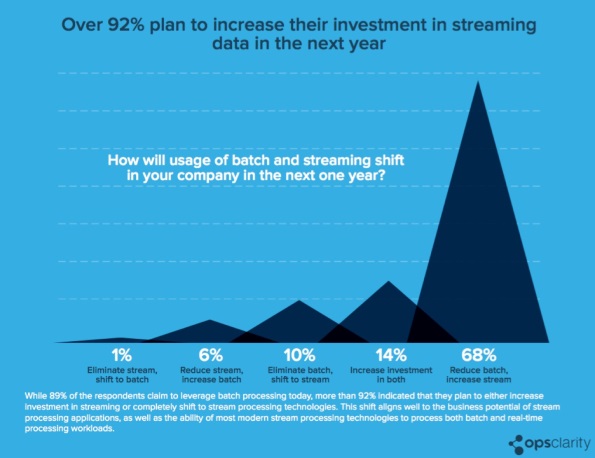
OpsClarity surveyed 4,000 individuals who were mostly developers, data architects or DevOps engineers and whom were all involved in development projects involving Big Data or fast data. Sixty-five percent of them said their employers already have near real time data pipelines in production. Another 24 percent plan to use streaming data by the end of 2016. Seven percent are evaluating but not using fast data, and just 4 percent said fast data was “not relevant.”
The survey found a shift from batch data processing to streaming data processing. Nearly 70 percent of respondents intend to reduce batch processing and increase stream in the next year. Fourteen percent will increase their investment in both types of data processing, while 10 percent plan to eliminate batch and shift to stream. Only 7 percent expect to either reduce or eliminate stream in favor of batch processing.
Barriers to Fast Data Adoption
But there are barriers to fast data adoption. Some 68 percent of respondents cited lack of domain expertise and complexity of the numerous data processing frameworks as major inhibitors.
Many companies use “an extremely heterogeneous collection of data frameworks,” Agarwal said. This is a dramatic difference from the recent past in which companies tended to standardize much of their data management infrastructure on a single vendor's platform.
As data types and data analytics use cases proliferate, so do data technologies. “I might use Cassandra when I want a columnar table, I might use Hadoop when I want long term storage, I might use Spark if I am doing a lot of data science,” he said. “I think this variety is here to stay.”
Unlike Oracle's popular MySQL database, which gets installed as a single unit on a single server, newer data processing frameworks are complex and distributed in nature, Agarwal said.
“Because Hadoop is fault tolerant, it makes multiple copies by default, so the underlying architecture is complex and distributed,” he said. “Coding and management are far more complex, and companies are struggling with it. There are strong business drivers to use these technologies, but companies are running into challenges. They are asking themselves: How do I find developers? And if I find developers, how do I make sure all of my systems are running reliably?”
In addition, he said, because batch processing occurs offline, failures are not nearly as big of a deal as those that occur during stream processing. “In the batch world, companies tend to do offline analytics that tell them how their business is doing. In the streaming world, there are a lot of real time calculations and these calculations can't go wrong. Monitoring and ensuring these systems are fault tolerant is becoming more important.”
The good news, Agarwal said, is that the underlying data processing technologies are maturing and software projects like Apache ZooKeeper, Apache Mesos and Kubernetes are introducing standardized management processes. In addition, he said, “monitoring systems like ours make sure companies get real time insights into distributed components so they can better understand what is happening and identify failures early on.”
Some other survey highlights:
- Respondents host data pipelines in the cloud (40 percent), on-premises (32 percent) and in hybrid infrastructures (28 percent)
- Respondents use open source distributions only (47 percent), both open source and commercial technologies (44 percent) and commercial products only (9 percent)
- For 33 percent of respondents real time data processing is 5 minutes or less, while 27 percent say it is 30 seconds or less and 19 percent say it is 30 minutes or less
Ann All is the editor of Enterprise Apps Today and eSecurity Planet. She has covered business and technology for more than a decade, writing about everything from business intelligence to virtualization.

Public relations, digital marketing, journalism, copywriting. I have done it all so I am able to communicate any information in a professional manner. Recent work includes creating compelling digital content, and applying SEO strategies to increase website performance. I am a skilled copy editor who can manage budgets and people.